

Introduction to Generative AI - Part 1
This is a series of blog posts on Generative AI and Prompting Techniques. This post serves as a introduction to the generative AI, its related techniques.

Introduction
This is an introductory blog post on Generative Artificial Intelligence and the very first post of the Generative AI blog series that I am going to make over the next few weeks. With the recent AI boom that's taking place right now, generative AI is the `buzzword` everyone is looking for. In this blog series, I will be talking about what generative AI really is, how it works under the hood to some extent, and see tricks and techniques on how we can leverage its potential.
To set the expectations: You'll see lots of YouTube videos, and education courses that are selling like hotcake which promises to teach you how to correctly use `ChatGPT`, and `DALL-E` to boost your productivity several folds, and how to suddenly make you smart to crack all data-science interviews out there. Unfortunately, I can't promise you that. What I can provide is to explain how most generative AI processes work under the hood, so that the "how to use it for your own purpose" can come to you naturally.
What is Generative AI
Generative Artificial Intelligence is composed of three terms: Generation, Artificial and Intelligence. Although the term was coined very recently, its related ideas was present in different forms for the last 50 years.
The word Intelligence comes from the Latin word Intelligere, meaning to understand. It literally means intelligence refers to the ability to comprehend complex things. It is one of the most significant gifts of evolution in the form of a large brain that sets us humans apart from Chimpanzees. Even the most trained Chimpanzees cannot perform more than very basic tasks such as identifying shapes, solving jigsaw puzzles, etc. (see here), but a five-year-old child can do significantly more than that.
With the advancement of computing powers, people have been trying to create machines that show signs of intelligence. Any such system is called an AI or Artificial Intelligence. Such a system should be able to prove that it is intelligent by demonstrating capabilities such as simple tasks like detecting shapes, solving puzzles, play games to complex tasks like writing content, and composing artistic pieces of music or paintings.
Among these proofs of intelligence, there are two kinds of proof:
Explicit proof: This is like writing an MCQ exam to prove that you have understood the concepts taught in the class. This is the case, where we design explicitly the problem that the machine needs to solve. For example, identifying the digit between 0-9 based on a picture of a handwritten digit.
Implicit proof: This is like asking you to write essays to test your literally skills. There is no correct answer that the machine should aim for, but the quality of the essay demonstrates its ability to comprehend and understand various topics.
The generative AI is an artificially intelligent machine designed specifically to give these kinds of implicit proof of intelligence.
Capabilities of Generative AI Systems
The implicit proof of intelligence demands us not to specify any specific problem with a definitive correct answer. So the capabilities that a generative AI system demonstrates can be many, some examples of these include:
- Natural language conversation: Ability to understand input message, understand and respond back.
- Image Generation: Ability to generate images/paintings based on ideas.
- Image Summarization: Ability to comprehend what is there in an image.
- Music Composition: Ability to compose musical pieces.
Before processing information, we humans collect the necessary data using our five senses. Similarly, a machine takes input using primarily three forms: Text, Speech and Image (or Video), and similarly, a computing machine also produces the output into one of these three natural forms. Based on these types of input-output combinations, we segregate the tasks that a generative AI perform into 9 different segments.
Under the hood of a Generative AI System
Imagine when you learn to draw, paint or ride a motorcycle, most probably you did not learn it right away. You tried to draw multiple times, you rode your motorcycle multiple times before you became good at it. So, to develop this kind of general intelligence, one needs to practice a lot, and sometimes see/experience lots of examples.
In mathematical terms, these examples are called samples, say we denote them by
i.e., you have n many examples. There is an underlying probability distribution p(x) from which these samples are usually collected independently (If you don't know what a probability distribution is, think of it as a mathematical description of the randomness that governs which examples you provide to the machine). Now, the aim of generative AI systems is usually, given enough training samples, to get an estimate
p(x) so that if you can generate a new example by sampling a random variable from the estimated probability distribution, it resembles "approximately" a sample generated from the original probability distribution p(x). So, internally, all generative AI algorithms are trying to get the estimate of p(x) as accurately as possible.
Under the hood, a generative AI system performs this in one of two ways.
Encoder-Decoder Model.
Actor-Critic Model.
Encoder-Decoder Type Model
Encoder-Decoder type of generative AI model mimics how humans understand a concept on their own. Usually, when you experience a list of examples, you try to summarize it in your head to remember the key points. And then, when it’s your time to perform, you use this summarized information from your head.
For example, when you want to write an essay on say "Global Warming", you may look up multiple online information for research purposes, multiple blog posts and essays. However, when it is time to write, you do not exactly copy it word by word, rather you comprehend the meaning behind the information, extract the keywords, and then paraphrase those concepts to write your final essay.
The same concept is applied in an encoder-decoder model.

Basically, the entire system is comprised of 2 parts. An encoder part and a decoder part. The encoder part takes in an example, and it extracts the key relevant information from the example. The decoder part takes the summary information and tries to reconstruct back the original example, as close as possible. Now, the idea is to make the dimensionality of the summary information significantly smaller than the size (or dimensionality) of the input example. Since the machine has to reconstruct back the original sample as it is, the encoder has to figure out ways to really compress the information to a great extent and only pass whatever is absolutely necessary.
For the math nerds, let z be a random variable denoting the summarized content. Then,
Now because z is a heavily compressed summary, it contains no auxiliary information. Therefore, all possible values of z are equally likely, (otherwise if some values of z are more likely than others, then this information could be captured through the compression). Another way to think of this is that you want this z to have maximum possible entropy so that they have maximum possible information, but this means z is uniformly distributed over its range (see here). Hence,
and hence, we have
Therefore, to estimate the probability distribution p(x) of the examples, one can try to learn the conditional probability p(x|z), i.e. an example given the summarized content. This is what the decoder tries to achieve.
The encoder is then just a supporting structure that helps to train the decoder by providing access to the summarised content z. This z is thus often called the hidden state of x in the encoder-decoder system.
Once both the encoder and decoder model are working in perfect harmony and can perform the reconstruction, you can now take the encoded part out of the picture. If you put in the summarized content but slightly perturb the values, voila! you get a new example from the decoder model.
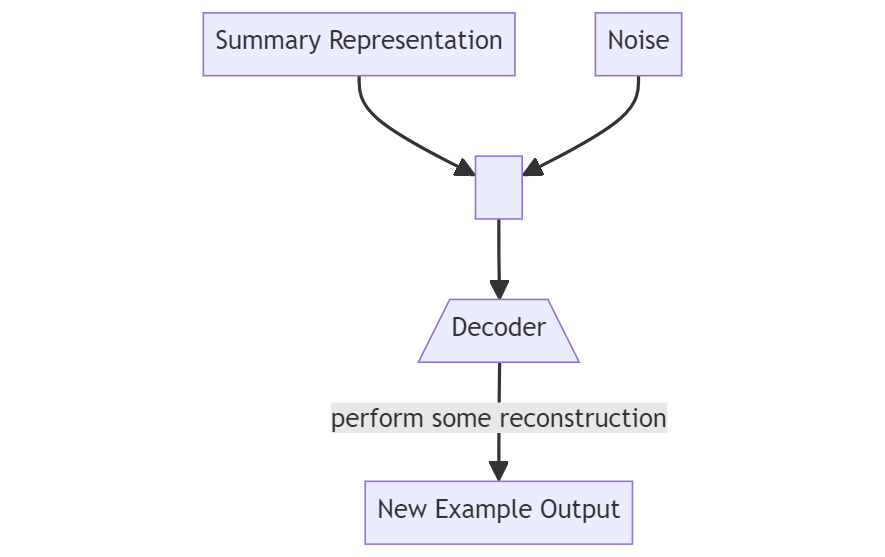
It is analogous to the following situation: Let's say you are good at painting. So, I pick up one portrait of a black-haired woman that you have drawn and I describe it to you for you to recreate it. But in my description, I mention her as a blonde, this in turn, allows you to create the portrait of an imaginary blonde woman instead.
Actor-Critic Model
The actor-Critic model in a generative AI system mimics how a human gets good at something (say painting) with the help of a master artist guiding him (her). The apprentice painter tries his (her) hand at making new paintings, sends them to the master artist, and then he (she) scrutinizes them carefully and sends feedback for the apprentice to improve upon.

Here again, we have two underlying modules in place: An actor machine that is entrusted with creating a new painting, and a critic machine that is entrusted to find problems in the new painting and provide feedback to the actor. Basically, the flow goes like this:
A random variable (often a standard Gaussian) is sent as an input to the actor module.
The actor takes this input, and using that tries to generate new examples (new paintings).
The critic module sees this generated example (painting), and compares it with some real examples (paintings from training data).
Based on how much similar/dissimilar they look, the critic provides a feedback score to the actor module, so that the actor module can improve.
These types of models are also often called Generative Adversarial Networks or GAN in short.
Again, to give you a mathematical perspective, often the starting seed value z is chosen from a standard normal distribution. In general, it can follow any reasonable probability distribution p(z) (with uncountable support). Then, we can again rewrite
This time also, the actor tries to estimate p(x|z) by its estimate similar to the decoder model. However, since it has knowledge of p(z), it can use it to estimate the true distribution
and finally, it generates new samples
as independent and identically distributed observations from this estimate and passes them to the critic model.
The critic model also sees original samples x₁, … xₙ coming from p(x). Hence, the critic model now has to perform a two-sample hypothesis testing to check whether p̂(x) = p(x) based on the two samples y₁, …, yₘ, x₁, …, xₙ. It then provides the p-value (or some kind of distance) as feedback to the actor model.
A simple example of such two sample testing criterion can be the Kolmogorov-Smirnov test, which also provides Kolmogorov-Smirnov distance as a measure of distance between p̂(x) and p(x). However, most existing models of this type use a neural network to approximate this distance function instead.
Comparison
Both of these two kinds of models have their pros and cons.
An encoder-decoder model can be used when you want to extract what kind of relevant example you want to generate. For example, it is useful when you want to perform natural machine translation say from English to French. Here, you do not want the actor to generate random text in French, but base the translation on the specific English phrase (i.e., Hello should produce Bonjour, not something else).
Actor-critic models are useful when you want to generate large amounts of similar data. For example, if you want to generate lots of images of different celebrity faces, actor-critic kind of models should be your first choice. Instead, if you use an encoder-decoder model here, due to the slight perturbation in the summarized content, you will end up with a lot less variation in the generated celebrity faces.
Actor-Critic models are usually notoriously difficult to train, but if they are trained properly, they are very powerful. Compare it to the analogy of training on your own (encoder-decoder) vs training from a coach (actor-critic). Training from a coach is difficult, but if you can master it, it is usually much better.
Conclusion
Most of the recent popular generative AI models (e.g. - ChatGPT, Claude, DALL-E, Stable Diffusion, etc.) are of the encoder-decoder type.
There are two reasons behind this:
The purpose you use it for is usually conditional generation, i.e., you give some kind of input based on which you ask the model to generate examples. It is as if you are doing this perturbation or giving the summarized information from which it has to start thinking.
Additionally, we see this surge of encoder-decoder-type models because they are relatively easier to train. This is because, in essence, the encoder-decoder type model is a compressing algorithm on steroids, so it is bound to gain some comprehension ability to compress the input information.
In the next post, we will dive deep into the encoder-decoder type of generative AI models and see how each kind of task `text-to-text` or `text-to-speech` or `text-to-image`, etc. is performed.
Feel free to share your feedback, stay tuned for more!