

Reinforcement Learning (Part 1) - K-arm Bandit Problem
This is an introductory post about reinforcement learning. Here I discuss about the exploration-exploitation dilemma with multi-armed bandit problem and potential solutions to this.

Why Reinforcement Learning
In recent times, we've witnessed an explosion of interest in Artificial Intelligence, particularly with the emergence of powerful Large Language Models (LLM) and AI tools like ChatGPT. Businesses and individuals are increasingly embracing this technology in various aspects of life, seeking to benefit from its impressive accuracy and extensive capabilities.
However, amid this excitement, there's a crucial concern often overlooked – the impact of these AI models beyond their neural networks to the real world. Let me illustrate with an example. Imagine you create a restaurant recommendation app using AI, which considers people's ratings, comments, and food quality of the restaurants to make suggestions. After releasing the app, it quickly gains 100 sign-ups on the first day – impressive, right? But here's the catch: the app keeps recommending only one restaurant as the best in town due to its high rating. As a result, that particular restaurant becomes overcrowded, leading to longer waiting times and, ultimately, a drop in its ratings.
The problem here is that if your AI model remains static and is trained only once, it cannot learn from new information and adjust its behaviour accordingly. However, with reinforcement learning, the model can continuously integrate feedback and improve itself day by day.
This is the first part of the Reinforcement Learning series of blog posts.
Follow StatWizard and subscribe below to get interesting discussions on statistics, mathematics and data science delivered directly to your inbox.
Introduction
Reinforcement Learning is one of the many paradigms of Machine Learning. Machine Learning, as the name suggests, means to enable a machine to learn how to solve a particular kind of problem. To understand the paradigms in machine learning, let me again draw an analogy. Imagine you are preparing for an exam.
You start by creating a cheat sheet for some question-answer pairs. If the same question comes up in the exam, you can answer, otherwise you cannot. This is logic.
You write another cheatsheet, but this time, with only formulas. If a question comes where the formula directly gives the answer, you can do it. Otherwise, you can't. This is an algorithm.
Now imagine yourself going to a teacher to learn about the concepts in the subject. When you make mistakes, the teacher is there is help you by providing the correct solution. This is called Supervised Learning.
Now suppose, you have studied similar topics before but not this one the exam is about. So when a question is asked, you try to relate it to one of the concepts you studied before. This does not let you answer questions but understand the relevance of the question. This is Unsupervised Learning.
Here, instead of learning about the topic, you just give plenty of mock tests. By giving so many tests and seeing their results, you start to understand what kind of questions require what kind of answers. This is Reinforcement Learning.
History of Reinforcement Learning
Here's a bit of a historical timeline of how reinforcement learning evolved over time, and if history bores you, feel free to skip to the next section.
1. Psychology and Behaviorism (Early 1900s - 1950s):
The concept of reinforcement and learning through rewards and punishments can be traced back to the early works of behaviourist psychologists such as Ivan Pavlov and B.F. Skinner. Their experiments with animals laid the groundwork for understanding how behaviour can be shaped and modified through reinforcement.
2. Control Theory and Cybernetics (1940s - 1960s):
Researchers in control theory and cybernetics, like Norbert Wiener and Richard Bellman, developed mathematical models to describe systems that adjust their behaviour based on feedback from the environment. These early theories laid the foundation for formalizing reinforcement learning as a field of study.
3. Dynamic Programming (1950s - 1960s):
In the 1950s, Richard Bellman's work on dynamic programming provided a powerful framework for solving problems involving sequential decision-making.
4. Temporal Difference Learning (1980s):
In the 1980s, researchers like Richard Sutton and Andrew Barto made significant contributions to reinforcement learning with their work on temporal difference (TD) learning.
5. Q-Learning (1989):
Gerald Tesauro introduced Q-learning, a model-free reinforcement learning algorithm, which sprouted some individual research about solving games using reinforcement learning.
6. Neural Networks and Deep Learning (2000s - 2010s):
The development of powerful computational resources and deep learning techniques revolutionized reinforcement learning. Researchers began combining deep neural networks with reinforcement learning algorithms, leading to the emergence of Deep Reinforcement Learning (DRL). Notable examples include Deep Q Networks (DQNs) by Volodymyr Mnih et al., and AlphaGo by DeepMind, which achieved remarkable success in playing complex games like Atari and Go.
7. Recent Advancements (2010s - present):
In recent years, reinforcement learning has seen incredible progress with innovations like Proximal Policy Optimization (PPO), Trust Region Policy Optimization (TRPO), and Soft Actor-Critic (SAC). Reinforcement learning is now being applied to a wide range of real-world problems, such as robotics, autonomous vehicles, finance, and healthcare.
Today, reinforcement learning continues to evolve rapidly, with ongoing research, new algorithms, and applications that promise to shape the future of AI and machine learning.
A Puzzling Toy Problem
Multi-armed Bandit
Multi-armed Bandit is one of the most popular problems to motivate reinforcement learning. Imagine you are in a casino, and there is a slot machine in front of you with k many arms. Each arm, if turned, gives a random reward. However, on average, some handles give more rewards than others. With the money that you have with you, you can only make use of the slot machine 1000 times, and within that, you wish to accumulate as much reward as possible.
Exploitation vs Exploration
There are two extreme strategies you can take up with this.
Exploit the greedy action to get the best possible reward based on whatever estimates about the stochastic behaviour you have on all arms of the slot machine.
Explore a non-greedy action to learn more about its stochastic behaviour and refine your estimates.
Clearly, with every turn of the arm, you can either choose to exploit or explore. You cannot do both.
Let us try to see the performance of these two approaches. To compare the performance, we will generate 2000 such 10-arm bandit problem. Here’s a bit of python code to do so.
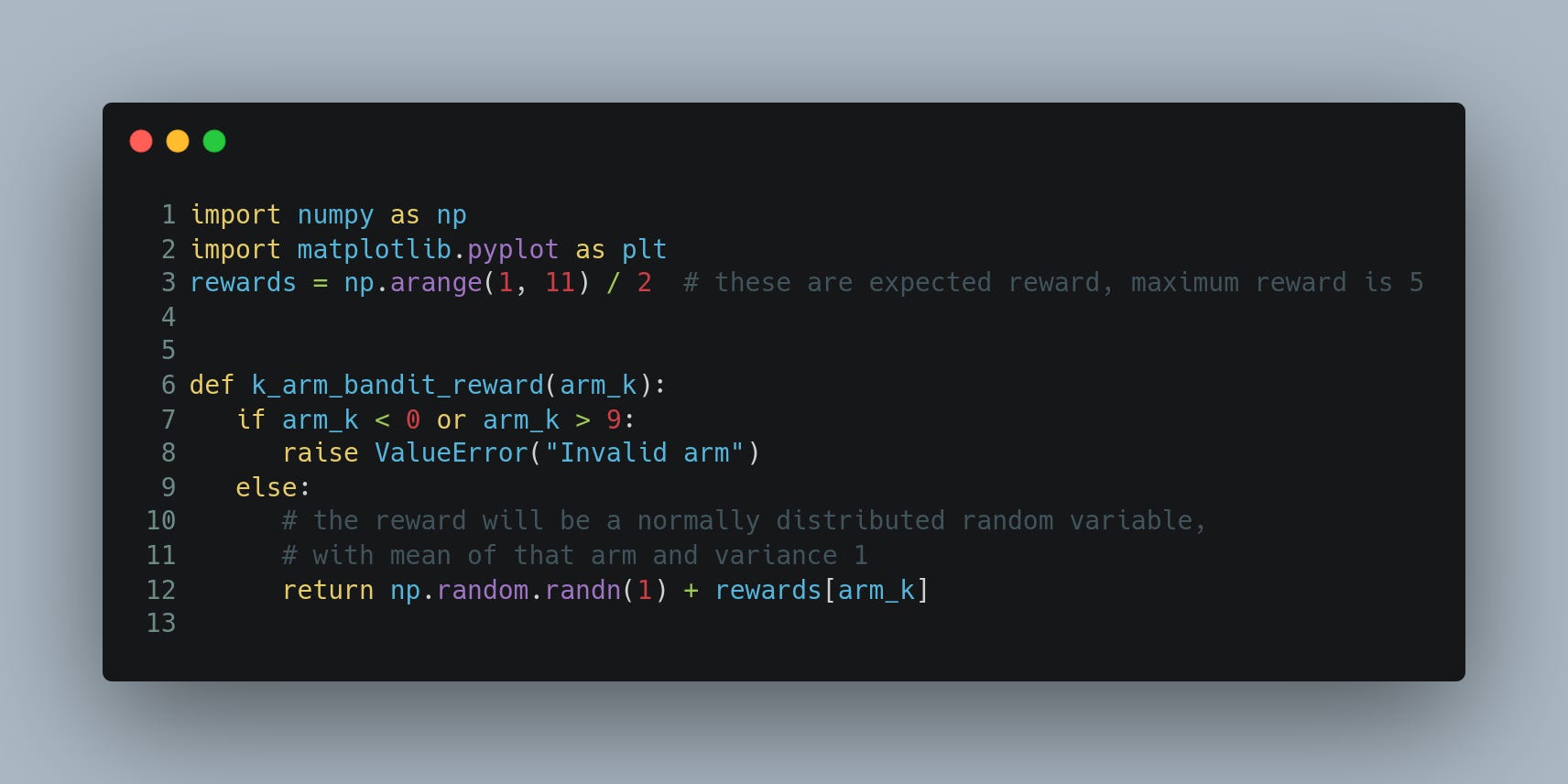
Here's a bit more of Python code that uses the first 10 rounds to get an initial estimate of the rewards of the arms, and then it continues to take greedy action with respect to the observed rewards.

Now we do the same for an extreme strategy that does only exploration.

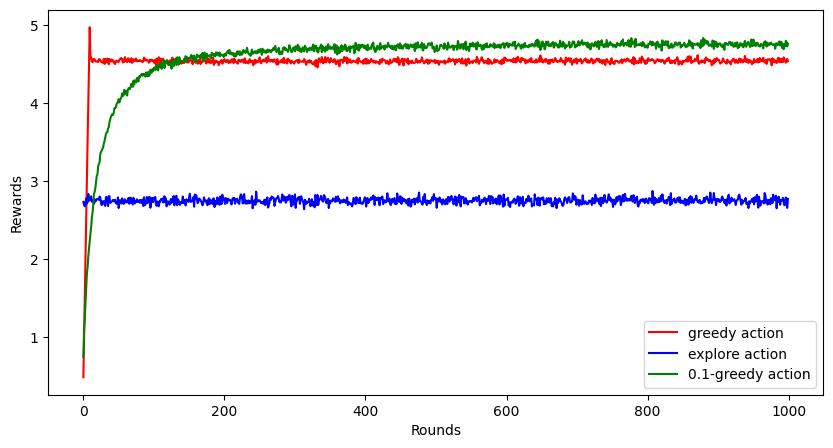
Here's the plot for the average rewards obtained by these two strategies over 1000 rounds.

Clearly, the greedy method performs much better than complete exploration at random. But notice that the greedy method cannot achieve the highest possible reward, i.e., 5 in this problem.
𝜖-greedy strategy
Looks like the greedy method does better, but it is not still optimal and there is room for improvement. This is because, often the reward from 8-th or 9-th arm turns out to be better than the reward for the 10-th arm at the first 10 rounds, and hence the exploitation strategy continues to take the suboptimal action throughout. It looks like we can do better if we explore sometimes to gather more information about the other arms.
So here's another strategy. You toss a biased coin with a probability of heads turning up as 1−𝜖 at each round. If it turns up head, you exploit based on whatever information you have. If it turns up tail, you explore randomly by turning one of the 10 arms, and then update the estimates for reward.
Here's a simulation for employing this strategy with 𝜖 = 0.1

Turns out, this performs even better than the greedy method. It achieves a higher reward closer to 5, but not exactly 5 even after 1000 rounds.
So, can we do better?
Since the 0.1-greedy strategy still does not always hit the target of 5, can we make it even better? Note that, the 0.1-greedy strategy always explores 10% of the time, even in the late rounds when the estimates of the reward distribution of the arms are known with high confidence. It does not make sense to explore that late in the game, and hence, we must keep reducing the 𝜖 parameter to reduce exploration over time (or number of rounds).
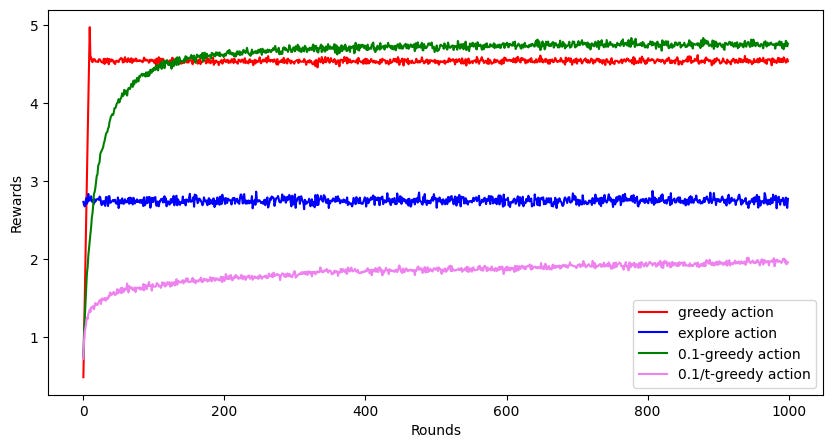
Here's the simulation with this strategy, where we take 𝜖 = 10/t, where t is the number of rounds. It is very similar to the code for 0.1-strategy shown earlier, with the only change

in the inner for loop with index variable `t`. As we had hoped, this performs even better than 0.1-greedy action.

Some Questions to think about
Here are some questions to think about and some things to try.
Why is there a sharp peak at the beginning for the greedy action, and there is no peak for the non-greedy actions which smoothly increases its average reward?
If we choose to reduce 𝜖 as 0.1/t instead of 10/t, it achieves a reward trajectory even worse than the extreme exploration. Why is that? Here's the visualization plot.
Where does this 𝜖 = 10/t come from? Can we use some statistical theories to dynamically come up with this rate of change to be applied on 𝜖?

I shall dive into the answer to these questions in the next post of this series. Till then, feel free to explore (or exploit) the answers to these questions and let me know in the comments.