

What new year resolutions is more trendy now? - Natural Language Processing Part 1

Well, another year passed by, and it is time to reflect upon what we had set out to do before, and what we have achieved in the last year. And again, it is time for a new year resolution.
One of my last year's resolutions was to write a tutorial series on Natural Language Processing, which, unfortunately, I could not do. So, this time, I thought, this is a perfect opportunity. We can analyze what kind of New Year resolutions people make, and then, what can we learn from there. Can we learn any changes in these resolutions year after year? And the basis of this analysis will be natural language processing.
For instance, ten years ago, New Year resolutions were simpler, like getting a job, or proposing to your crush, and so on. As far as current resolutions go, I see different trends, like going to the gym and getting healthy, achieving FIRE, etc. across social media platforms. Can we analyze some data and understand these patterns somehow, instead of relying on our gut feeling?
The Dataset
So, here are some interesting datasets that I could find.
A dataset containing 5011 tweets on New Year resolutions from 2014.
A similar dataset containing 100K tweets at the end of 2021.
If you look at any of these datasets, you will find a bunch of tweets (we will call them “posts” of X from now on, to not trigger a certain someone 😝 — you know who!). The goal is then to analyze these texts using methods of statistics and natural language processing to better understand them. My plan is to do this over the course of the next few weeks as a tutorial series — and explain different concepts from NLP along the way.
Let’s start with the basics.
Why language processing needs separate attention? What’s so special about it?
If you look at human evolution, you will find evidence that we began to count far before than started to develop language to communicate. If you look at a baby, (s)he can recognise the difference between one toy or two toys, without still being able to communicate about physical needs of hunger or sleep to its parents in his (her) native language. So, at least to us, mathematical ideas are far more fundamental than language itself.
With the same principle in mind, when people designed a computer, they thought of it as a computing device - like a calculator, though now, it can do far more than what a calculator can do. However, the basic design of a computing device only allowed computers to perform numerical operations. Language differs from these numerical systems in some fundamental ways.
Numerical systems are exact, they convey the same meaning to everyone using such a system. An American would count a square having 4 sides and so will an Arabic. However, in language systems, for instance, the standard method of writing in English would be left-to-right while the standard method of writing in Urdu is right-to-left.
Numerical systems are intrinsic in nature. They don’t require any additional context to make sense. However, understanding language often demands knowledge of a context that is “external” to the language system itself. It is generally understood that the practitioner of that language is well-versed in that knowledge. For example, consider the word “model” — which has two completely different meanings based on whether you are a statistician or a professional photographer.
Given two numbers, “a” and “b”, either they are equal or not. There is no middle ground. If they are the same, then in all contexts you use “a”, you can replace by “b”. But it is not true for language, you do not have this nice replacement property. For example, “he finally kicked the bucket” and “he finally kicked the can” have completely different meanings.
Hence, to process these ambiguities present in language, we need to treat them slightly differently than how we treat numbers, and we will see more later on what ways these treatments differ.
So much I have blabbered about, now let’s try to see action with the dataset.
Tokens and words!
The smallest part of a text that has some sort of meaning are “words”, and we call them in natural language processing as “tokens”. Let’s try seeing what tokens we have in the first dataset containing the posts.

What we are doing here is simply segregating each of the posts into multiple tokens by splitting them with space, and then maintaining a counter for each word. Let’s try to now look at the most common words in this.

It turns out, there are about 14869 unique words, and the most common words are as follows:
“#NewYearsResolution” with count 3410
“to” with count 3031
“is” with count 1375
“I” with count 1354, and so on.
Clearly, these words are kind of expected, they don’t give us any new information about what kind of New Year resolutions were more popular back in the days of 2014-15.
Let’s also look at some of the least-occurring words.
“it??_” with a count of 1.
“#NoExcuses” - with a count of 1.
“@sammymewy:” - with a count of 1.
“appreciated.:)” - with a count of 1.
Again, we see a bit of an issue here. There are punctuations, mentions, and hashtags, all of which need different types of processing. Let’s see how each of these special tokens affects our analysis of the trendiest New Year goals.
Mentions will contain the X account names, which does not give any meaningful information in knowing what the goal is about, in general.
Hashtags may contain some good understanding of the trends in general, so we will remove the hash character from the tag and treat that as a word.
For punctuations, we will replace them with blank spaces. This will lose some information, like information about emojis, but analyzing words such as “appreciated.:)” will be a lot harder.
In addition to these, also we would like to remove some of the very common words in English, like articles (e.g. a, an, the) and prepositions (e.g. to, from) from consideration, as they won’t have any meaningful contribution in understanding the trends. These words are often called “stopwords” in natural language processing.
So we use the following Python function to clean up the posts.

And at the end of it, if we again calculate the frequency of words and look at some of the most common words, we find:
The word “newyearsresolution” - appears 3948 times.
The word “new” - appears 1588 times.
and so on. Clearly, we are not there yet, something is still missing.
The Balancing Rule of tf-idf
Let’s look at a word like “newyearsresolution”. Why exactly this word does not provide a meaningful pattern to know what kind of New Year resolution people are talking about?
Because this word will be present in almost all the posts.
This means, that in addition to the frequency of the words in the posts, we should consider how many posts each word appears in. This is called “document frequency”, as opposed to the “term frequency” or “token frequency” that we have been calculating above.
Here is a REALLY INEFFICIENT way of calculating this.

And then, if we look at both the “term frequency” and “document frequency” together, we find the two extremes.
Words that have any high document frequency appear almost in all posts, and they will show high term frequency as well. These are not useful to us.
Words that have less document frequency appear in much less number of posts, they have less term frequency and do not tell us anything about the trend.
Therefore, more of both term and document frequency is bad for us, as well as less of both. We want something to balance both of these.
One way to do this would be to create a combined metric, given by
where N is the total number of posts. Note that, taking the inverse of document frequency means high value will adversely affect the score, which is what we want. However, the logarithm ensures that even if document frequency is very small, i.e., the word is “rare” and appears in a single document, the score is not increased too large, and its effect is gradually diminished by the logarithmic function. A more detailed explanation comes from this 1972 paper by Karen Jones on the specificity of information retrieval.
Note: The above formula is not the “standard” tf-idf that is calculated by SkLearn package. Tf-idf is usually calculated for a pair containing a document and a token. Here, we considered an aggregated tf-idf for each token, which is aggregated over all documents. In the next few posts of this tutorial series, we will see the connection between these two concepts.
At this point, we have the term (or token) frequencies and the document frequencies, and we would like to combine them together and calculate the tf-idf scores as mentioned above.

Finally, to understand the most important keywords to look for, we can look at the words in the decreasing order of this aggregated tf-idf scores. And, instead of looking at a plain old table, we can do something much cooler, create a word cloud. It is a graphical representation of a bunch of words, where the size of the word represents a score. So the words with huge fonts become the most prominent keywords! Here’s a bit of Python code to create WordCloud.
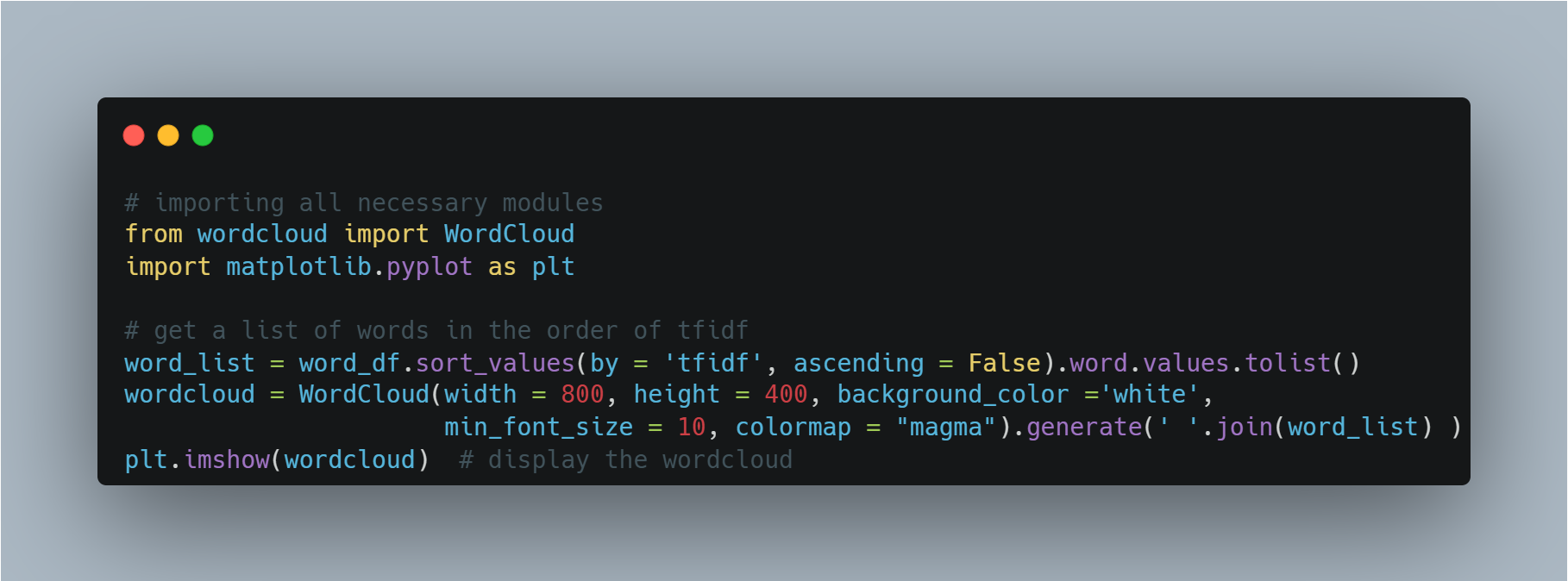
Here’s the output word cloud that came out from all New Year resolution posts (the then tweets)…

Some key patterns could be:
“Stop” for a moment and “take” all in and “think”
“Stop” doing a bad habit.
“Make” “time” for something/someone you “like” / “love”.
“Take” a “day” to go “workout” or go “eat” out.
I did the same analysis for the 2021 X posts as well, and here’s the resulting WordCloud turns out to be…

Based on the keywords, we can guess many of the posts are possibly related to the end stage of the global coronavirus pandemic (notice the word “covid” coming up inside the big “e” in the word “make”). Some posts could be lamenting about people’s lives that were lost, making people come back to the office and work, and so on.
Conclusion and Next Steps
In this post, we understood some very basic steps of natural language processing, learnt about tokens, and discussed the importance of text cleaning and preprocessing. We learnt about stopwords, term/token frequencies and inverse document frequency (idf) and calculated an aggregated tf-idf score to identify keywords. We finally saw how a graphical representation like WordCloud can uncover some hidden patterns present in the data.
However, still, some crucial problems remain:
In the 2014-15 posts, consider the word “eat”. We don’t know what kind of sentiment is associated with it, which is a key ingredient in understanding what kind of New Year's resolutions we are talking about.
For example, it could be “to stop eating unhealthy food”.
Or it could be “to make time for going out to eat with friends”.
Without the understanding of the sentiment, (or the negation connotation), we are only left guessing.
In 2021 posts, although we see some keywords, it is very difficult to make sense of the resolutions that may combine multiple keywords to form. For example, both “last” and “first” appear with a large font in 2021’s word cloud — I am not particularly sure about how to interpret the appearance of these keywords.
In the next posts, we will try to tackle this problem and aim to uncover more hidden truths lurking inside these New Year resolutions!
Thank you very much for being a valued reader! 🙏🏽 And wish you all a very happy new year for 2025!
Subscribe and follow to get notified when the next post of this series is out!
Until next time.
I liked the post and read it line by line, but I didn't got the formula , it would be nice if you can explain that in depth.