

Attention for understanding sentences - Natural Language Processing Part 6

Introduction
In the last post, we learnt together about RNN, LSTM, GRUs (if these keywords are new to you, maybe you want to read the previous parts first, at this link to the post) and saw how they draw various analogies from the human brain to build a neural network system able to understand the meaning of texts. However, we process words slowly, one word at a time, and this may be too slow when we have a vast amount of computing power at our disposal. In this post, we explore the concept that reshaped modern natural language processing: Attention — a simple but powerful idea that lets models take a peek at the entire sequence of input words all at once, and only “attend” to specific parts as it sees their relevancy.
Attention: What is it, and why is it so powerful?
Before delving into answering the question, I will start with a story (a version of the story is also available here) that I’ve heard some time back at a programme at Ramkrishna Mission.
During his visit to Chicago, Swami Vivekananda used to visit the library to learn about various religious practices across the world. He used to borrow multiple books from the library and then return them the next day, and again borrow another set of books. After this continued for some time, the librarian found this pattern very strange, and was quite annoyed by his behaviour. So on the next day, when Swamiji came to return the books, the librarian confronted him and asked him about this behaviour. Swamiji replied that he could read all these books he borrowed in one day. The librarian could not believe, so he challenged him by picking out a random page from the books he borrowed last day before and started asking him questions from that page. Swamiji was able to answer each and every one of them — and sometimes even with more explanation about the gist written in the book, on that page. When asked about how he did it, Swamiji replied that: “When we are children, we read letter by letter, then we start to read word by word, and with some practice, maybe 2-3 words at a time. Swamiji reads passages by passages”.
Now, although we don’t know what technique Swamiji was using, but one thing is clear is that reading word by word is extremely slow, and with enough practice, one would be able to glance at a sentence or a paragraph and then consume all the words in it simultaneously. This insight is what gave birth to the “Attention mechanism”.
Let’s say you are reading a long sentence.
“The book that the professor who the students admired wrote was insightful.”
To understand what was insightful, you kind of move back and forth in this sentence to find the most relevant word to pay attention to, and only then you would know it is “the book”. However, while scanning the sentence, you only attend (for test) to a few words, namely “the book” or “the professor” or “the students” — which are nouns or pronouns that qualify to be “attended" to.
Let’s try to see how all these intuitions mathematically play out.
The First Glimpses of Attention
While "Attention is all you need” is the most popular (currently, it has 178 thousand citations) among the papers that introduced attention-like technology, it was not the first of its kind. Before the Transformer stormed the stage, researchers were already experimenting with the idea of letting models dynamically focus on important parts of input — particularly in neural machine translation.
Bahdanau Attention
The first “attention” architecture was proposed by Bahdanau, Cho and Bengio in this 2015 ICLR paper. Let’s say you are trying to translate a sentence in English, “How are you?” to its French translation “Comment vas tu?”. The neural network encoder takes in the words “How”, “are” and “you” and produces hidden states:
After processing “how”, the encoder has a hidden state h₁
After processing “how are”, the encoder’s hidden state changes to h₂
After processing “how are you”, the encoder’s hidden state changes to h₃
Once the encoder processing is finished, the decoder takes it up.
It picks up the last hidden state of the encoder h₃, predicts the first word of French “comment”, and modifies the hidden state to s₁
Next, using the state s₁ it predicts “vas” and modifies the hidden state to s₂.
Finally, using the state s₂, it predicts the word “tu”, and modifies the hidden state to s₃.
Using s₃, the decoder neural network predicts the end-of-sentence token and stops.
During this processing, let’s look at what happens for the decoder when it is taking state s₂. At this point, it should be understood that it is predicting the French translation of the word “you” — so this is the word the decoder should really pay attention to. So, at the decoder end, we compute the similarity between s₂ and all the intermediate hidden states that have been processed by the encoder, using the following alignment formula:
where v, W₁, W₂ are parameter weights that are trained. Ideally, s₂ should be “close” or “similar” to only “h₃” compared to its similarity with h₁ or h₂, as only h₃ has seen the word “you” and stored its meaning; therefore, we expect a(s₂, h₃) to be large. And then a context vector is computed as
which is basically a weighted linear combination of all the intermediate hidden states, with the weights being exponential of the affinity scores. So if the affinity score is large, then the corresponding weight is close to 1, and hence, the context vector will pick out only that intermediate hidden state, e.g., h₃ here.
And then we modify the decoder as a neural network that takes this context vector cᵢ (which is the specific attended hidden state) and also the current state s₂ to predict the word “tu”, as opposed to taking only the current state s₂.

Luong Attention
Luong, Pham and Manning, a group of researchers from Stanford University, came up with another attention mechanism around the same time, as described in this paper. Their ideas made 2 improvements on the works of Bahdanau et al.
One problem with the attention as described in Bahdanau et al. was that all the intermediate hidden states h₁, h₂, … need to be saved in order to compute the context vectors cᵢ. So, if you are translating a longer sentence (or a paragraph) with 100 tokens, then you need to store 100 intermediate states, which can be challenging. So, Luong et al. suggested that we can use a “localised” attention instead, which only stores the last K number of intermediate states, and only considers them. One way to implement this technique is to use an LRU cache, which removes the oldest intermediate state whenever we proceed to the next token.

The above diagram from the paper by Luong et al. nicely summarises the concept of using “local weights” taken from the linear combination of only the “localised” neighbourhood of the token we are trying to predict.
Also, the Bahdanau et al. introduced three new parameters v, W₁, W₂ — the weights used to compute the affinity scores. Increasing the number of parameters is always a challenge because it requires more training data to train the neural network. Luong et al. proposed two simpler variants of affinity calculation:
The first choice uses a single weight parameter, while the second one uses no parameter, both reducing the computational burden of the neural networks.
While Bahdanau and Luong attention mechanisms improved translation models, they still relied on RNNs' sequential processing. The next breakthrough came when researchers asked — can we eliminate sequential dependencies altogether?
Transformers - the big game changer
Transformers is a version of the attention based neural network architecture, which was proposed in the seminal 2017 paper “Attention is All You Need” by Ashish Vaswani and his colleagues at Google Brain. The name of the paper kind of gives the entire spoiler — it aims to make Recurrent Neural Networks faster by removing the sequential dependencies, and instead relying completely on a “self-attention” based mechanism.
Before moving on with the transformer architecture, let’s think of an analogy from Star Trek. Say you are learning Klingon, and you went to a Star Trek convention. At this point, you find some object which you like in a convention shop, so you are thinking of asking for the price of that object. Unfortunately, you don’t remember the exact “word” for that object in Klingon. So, you would probably relate that “object” with existing “concepts” for which you know the proper Klingon translation. Here, the “object” is the query (you want the answer for), the related “concepts” are the keys (or called the context), and their translation in Klingon is the values.
The transformer architecture uses a scaled dot product formula to calculate these affinity scores between the query “object” and the key “concepts”. As a result, for each word using self-attention, we express it using “concepts” from the other words as
Here, d is the dimension of the vector Q.
Now, when you are predicting the next word, clearly you will not know the “future” words, hence ideally for the i-th word, you should consider the above linear combination only up to the (i-1)-th word. Therefore, for a word Q at position index “i”, the authors consider
Finally, they see that the neural network’s performance increases when there are multiple spectra of “concepts” it relates to — i.e., there are multiple (Q, K, V) triplets for each word. These are obtained by using a simple linear projection of the original word, where the projection weights are trainable parameters. You may think of this as when describing that “object” in Kligon, you may take concepts from the Star Trek show (like describing which episode it was used in) and also from geometry, to talk about its shape and colour.
Since this considers multiple attentions (one for each type of “concepts”), this entire system is called a “Multi-Head Attention”. Then, these attention outputs are concatenated together and passed through a final linear neural network to reduce the dimension. As is clear from the description, there is no sequential dependency involved — instead, using the positional index, it computes multiple partial self-attentions for each token in parallel, and then simply combines them. This becomes “One Attention block”.
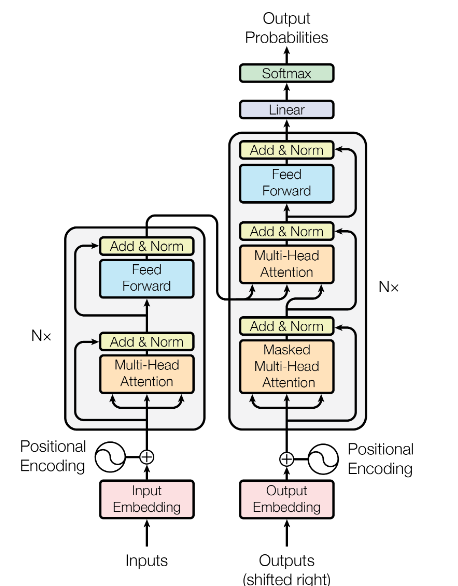
In the above diagram of the neural network from the original Transformers paper, we see that it says N times the attention block in the neural network. Originally, the authors considered N = 6 stacks of layers.
According to this paper, the GPT 3.5 model (which was popularised and considered to be the starting point of the large language models) had a whopping N = 96 layers of transformer architecture.
While we see that GPT responds to us in near-instant time with a properly curated answer, it is worthwhile to understand the enormous computation it needs to go through — and much of it happens in parallel because of this transformer-based structure, which completely removes the sequential dependency.
Conclusion
So far, we have only talked about the encoder part of a neural network-based natural language system and how they are designed to extract the meaning of a sentence efficiently. In the next post, we will talk more about the decoder systems, which is also an integral part of language modelling. We shall also see what new technologies are available at the decoder side, and how they are evolving in modern AI research.
And as always, thanks for being a valued reader! 🙏🏽
Until next time.