

Reinforcement Learning (Part 6) - Value Function Approximation
This is the 6th part of the Reinforcement Learning Series: Here I discuss about techniques to work with infinite state space, where the tabular methods do not work.

Introduction
It's been a while since I made my last post on reinforcement learning. Here's a brief recap: In the last post, we learned about the Q-learning algorithm. Q-learning is a variant of temporal difference learning, that combines both the Monte Carlo type algorithm where you experience the rewards, and also the Dynamic Programming algorithms where you theoretically calculate the expected value of each state using recursion techniques. Here’s the post link in case you missed.

However, so far whatever we have discussed has a major drawback: It requires both the state space and the action spaces to be finite and discrete. This means you can create a table of rows and columns; rows denoting each state and columns denoting each action you take, and in the cell of the table, you can keep updating the value of the state-action pair. Due to this, when solving the acrobot problem from “OpenAI gym”, we had to discretize the state into buckets. This is often called sparse encoding of a continuous variable, more on this later.
For now, we will try to solve another reinforcement problem from the `gymnasium` package, called Mountain Car. The goal of this problem is to move a car up into a mountain starting from the bottom of a valley, while gravity works against the car pulling it downwards. At any point, two state variables are available: the position of the car and the velocity of it. Based on this, the car has to determine whether to try to move to the left, or to the right, or do nothing and let gravity and the car's acceleration do the magic. The car is asked to move to $200$ turns, every turn gives a reward of (-1) unless you reach the goal above the mountain top to get a reward of 0. The goal thus becomes to reach the mountain top as fast as possible. You can read more about the environment here.
Here's a GIF about an unlearned agent randomly trying to move left or right.

Unfortunately, the tabular methods (you should now be able to guess why it is called tabular! 😎 ) discussed so far cannot handle this environment, since we have two continuous variables (velocity and position) as observations. Instead of the tables, we now need to learn a function approximation that takes in a state and action pair and output the q-value for that pair.
Since Q(.) is unknown, we usually take linear, polynomial, logistic functions, random forests or neural networks to approximate the Q-function, and all of these approximations work based on finding some correct weights or parameters for those models.
This is the sixth part of the Reinforcement Learning series of blog posts.
Follow StatWizard and subscribe below to get interesting discussions on statistics, mathematics and data science delivered directly to your inbox.
Linear Approximation
Representation
Let us look carefully at the Q-learning update step,
which we can rewrite as
for some learning rate 𝛼 and discount factor 𝛾. This expression tells that the updated Q-value is simply a convex combination of the old Q-value and the target (rₜ₊₁ + 𝛾 𝑚axₐ Q_{old}(sₜ₊₁, a)) Hence, every such step is taken such that the current Q-value moves a bit towards the target, and the ultimate goal is to make sure that the current Q-value matches with the target. If it matches for some Q*, we will have Q∗(sₜ, aₜ) = (rₜ₊₁ + 𝛾 𝑚axₐ Q∗(sₜ₊₁, a)), which is exactly same as the Bellman's optimality equation introduced earlier. See my previous posts if you don't know what the Bellman equation is.
Now consider a linear approximation to the Q-value. Hence, instead of creating a table, we consider the special form
where W is an unknown weight. To see this for our Mountain car problem, imagine this:
where w₁₁, …, w₃₂ are unknown weights that the agent will learn over time. We can also compactly write its form by collecting these weights together in rows,
and a matrix multiplication between W and the vector (position, velocity) of the car will give us the Q-values for all 3 actions at once. Here's a Python code that implements this idea.
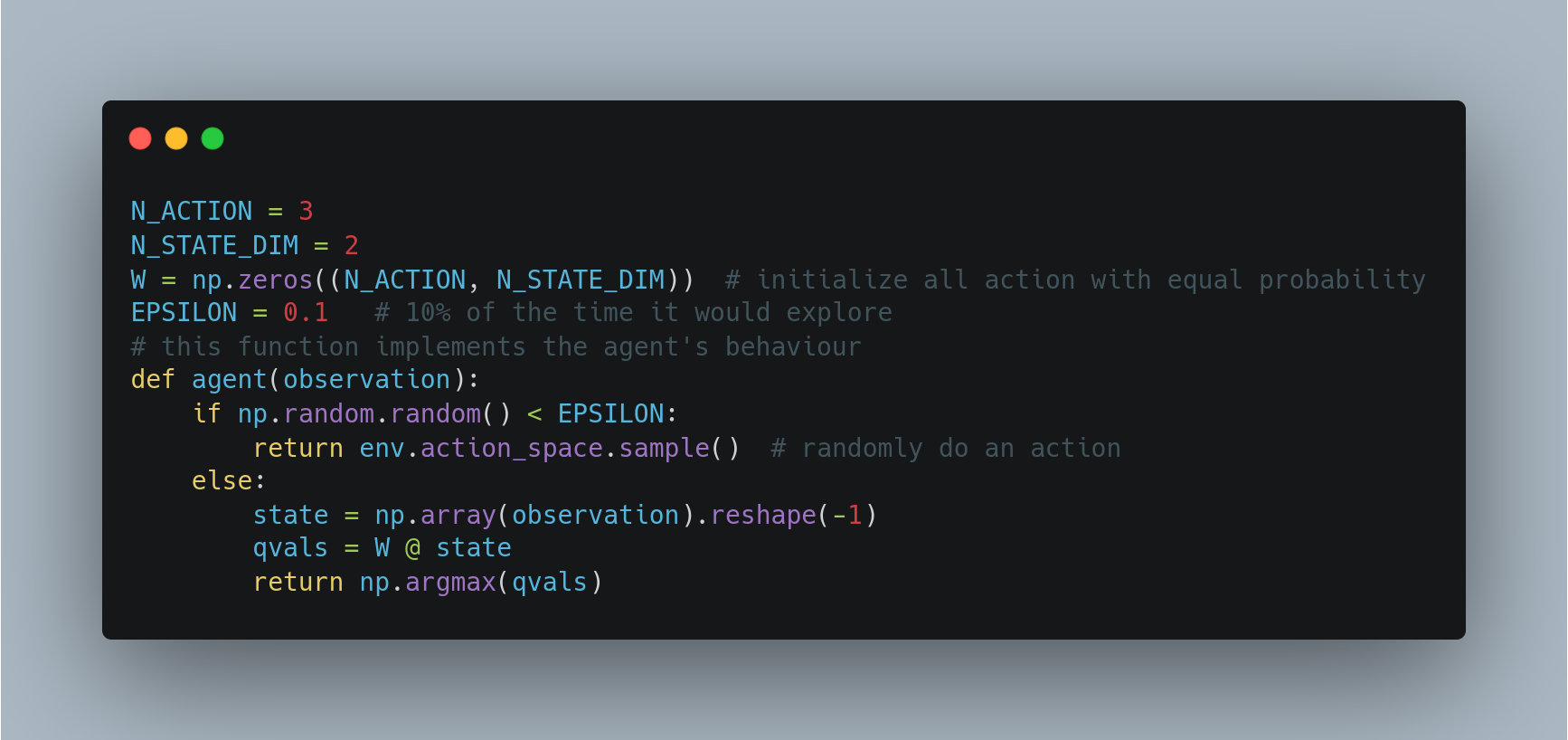
Learning the Weights
Now how do we actually learn the unknown weights? As mentioned before, we want the Q-value to be such that it satisfies the Bellman equation. So we want the error squared (i.e., the target minus the current Q-value difference squared),
to be as small as possible (We take square to ensure negative errors also impact positively). Since we want to minimize this error with respect to the weights w, and for that we can take the derivative of the error with respect to the weights w and set its value equal to 0. (You might want to see some refresher courses in elementary differential calculus.) The derivative of this error turns out to be
Here, ∇f(sₜ, aₜ;w) denotes the gradient (or the derivative) of the function f with a special form. We will figure this out for the linear case in a bit. Since the derivative tells you the slope of the curve and how the errors are changing, you actually need to go in the opposite direction of the slope to reduce the error. To see this, consider the case when ∇f(sₜ, aₜ;w) is positive (I know the pedantic math folks will scream here! but just bear with me for the sake of explanation). It means increasing w will increase the value of f(sₜ, aₜ;w). When f(sₜ, aₜ;w) is more than the target, then the error is positive, hence we would want to reduce the f(sₜ, aₜ;w) and hence the weights w, which can be achieved by taking a step towards the negative of the above expression of the gradient. On the other hand, if f(sₜ, aₜ;w) is less than the target, then we want to increase f(sₜ, aₜ;w) by increasing the value of w, which can be again achieved by taking a step towards -f(sₜ, aₜ;w) - target which is positive, hence increases w.
The case when ∇f(sₜ, aₜ;w) < 0 can be explained similarly, you might want to ponder a little and convince yourself about it.
Finally, we can use the update rule;
This is often popularly known as the Gradient Descent Method. This is often used as a general-purpose optimization routine to minimize or maximize any differentiable function. For the linear function case in the Mountain Car problem,
and hence ∇f(sₜ, aₜ;w) becomes the state vector itself. So, here's a Python code that implements this update step to train an agent for the Mountain Car problem. The code is similar to what we did before, so you should be able to follow along.

Most of this is standard that we have done before for the Q-learning case. However, you can see that the value of the target differs a bit here compared to the Q-learning, if you pay close attention to these lines.
new_action = agent(new_observation) # get the next suggested action as well
target = reward + DISCOUNT_FACTOR * np.dot(W[new_action, :], new_state) # now do the weight updateInstead of taking the action with the maximum Q-value, it generates the action from the agent itself and considers its Q-value as the target. This means now the updated equation is
Notice that maxₐ is replaced by aₜ₊₁, to ensure a bit more exploration compared to Q-learning. This method is known as SARSA (State-Action Reward State-Action) in Reinforcement Learning Theory.
Here's the trained agent after 5000 episodes of learning.
Huh! 😟 Not very impressive! It is trying to move to the right and pull the car up, but gravity is continually pulling it downwards. So, we need to do a bit more.

As you can see, the agent is sometimes reaching the goal (receiving higher rewards than 120), but it is not continually improving.
Nonlinear Encoding
So far, we have only two features as the observations from our environment; the position and the velocity. If you know a bit about Newtonian mechanics, you would be able to guess that a linear combination of position and velocity makes no sense, they have different units altogether. You might want to take squares, multiply them with the mass of the car, adjust for the acceleration by gravity and do all kinds of stuff. All these operations are nonlinear functions of position and velocity; so the linear approximation that we considered as the beginning might not work.
However, we can extend the idea and consider something like this:
or take
or take even higher powers. All of these are called encoding of the observation features. Once we encode and create these new variables (position, position², and so on), we can use the same technique described above to train an agent, but will much more nonlinear information.
Sparse Encoding
Here's a brief review of sparse encoding. Let's say you are giving an exam, where you have a score between 0 to 100, but the course requires you to have a grade of B or above. This grade is a sparse encoding of the continuous marks that you have achieved.
If the score is more than 80, give a grade of A.
If the score is between 60 and 80, give a grade of B.
If the score is between 45 and 60, give a grade of C.
If the score is between 30 and 45, give a grade of D.
If the score is less than 30, give a grade of E.
This certainly helps, because your passing depends on the grade, not of the actual score. But it may not be the case always. For example, consider the problem when you want to determine if a person has some debt based on his / her earnings. Usually, people with very little money and people with very much money have lots of debt (clearly, for separate reasons, the first set for sustaining survival needs and the second set for making more money 😏 ). However, most people in middle-class families usually fear debt a lot, and they have very less amount of debt. They take debts for buying a car or house, but that's about it. Now in this kind of situation, the output (whether they have a debt or not) is not a completely known function of their earning grade. In such cases, we need to move beyond sparse encoding.
Kernel Encoding
In the sparse encoding, the basic idea is that close values of position and velocity should be encoded into the same bucket and hence would have the same action. This means the RL agent would want to learn how similar two (position, velocity) pairs are from each other rather than the exact values of the position and velocity. To work with this idea, imagine that there is a nonlinear map 𝜙 that takes the input position and velocity and outputs some feature, and the quantity of interest is
where K is some function that measures the similarity in the 𝜙-transformed space. Hence, rather than individually specifying 𝜙 explicitly, it is often enough to specify K alone which can produce a nonlinear mapping from the observation features to a new set of features. The function K is called a kernel.
Solving the Mountain Car Problem
In our mountain car problem, we consider the Gaussian kernel
with different values of 𝜎². Before passing to this Gaussian kernel, we also do a normalization step which will ensure that the observed position and the velocity has an average close to 0 and a standard deviation close to 1. Here's the Python code that implements this feature encoding.

So now we have a whooping 400 nonlinear features derived from only two variables, position and velocity. This might be an overkill, but let's see how it performs. Before that, I just want to indicate the lines that needs to be changed in the RL training for this.
This is the function that converts the position and velocity into 400 features.
def get_obs_feature(observation):
scaled = scaler.transform([observation])
featurized = featurizer.transform(scaled)
return featurized[0]Other changes include, our weight matrix being a bit big, the creation of features from states, and appropriately modifying the update statement.
N_STATE_DIM = 400
W = np.zeros((N_ACTION, N_STATE_DIM)) # initialize all action with equal probability
...
feature = get_obs_feature(observation)
new_feature = get_obs_feature(new_observation)
...
target = reward + DISCOUNT_FACTOR * np.dot(W[new_action, :], new_feature) # now do the weight update
W[action,:] += LR * (target - np.dot(W[action, :], feature)) * feature # the gradient is now entire 400 dimensional feature vectorWe just trained it for 200 episodes, and here's the result.
Cool! So, just using a bit of nonlinearity, we could train the RL agent much faster.

And this shows that the RL agent is continually learning to increase its rewards, and learning how to reach the goal.
Questions to think about
Here are a few questions to think about before my next post.
1. What if we use more complicated algorithms rather than linear algorithms? What about using deep neural networks?
2. How do we know what kind of encoding to use for which problem?
We will explore and try to answer some of these questions in the next post of the Reinforcement Learning Series.